
info@andornot.com
1-866-266-2525
We love choosing or developing software to meet the unique needs of each client. We take pride in creating solutions for every budget, large and small, and for every information management need.
Whether it's commercial off the shelf software, open source or something we develop just for you, we'll find the right application to help you manage and search information.
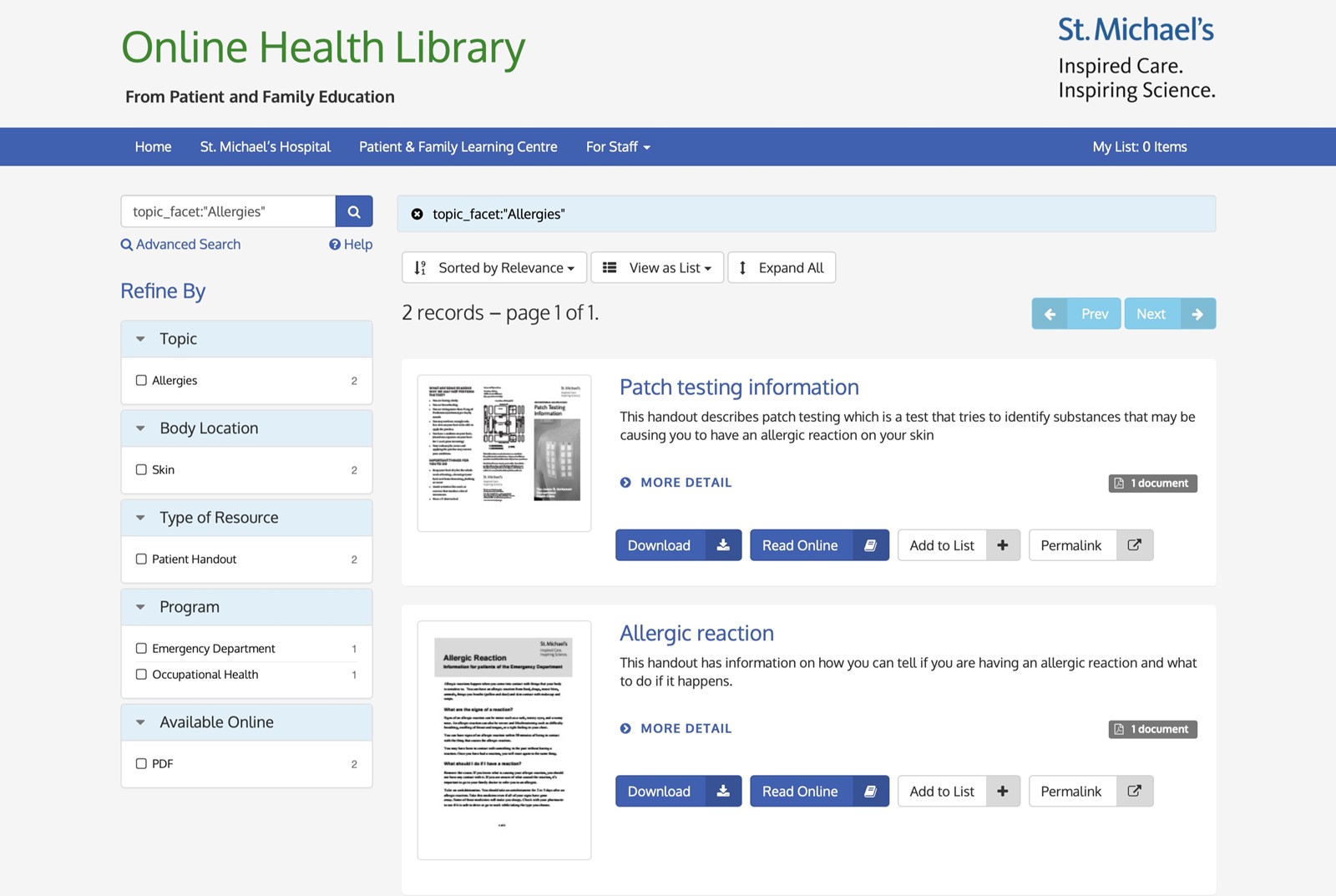
Andornot is an authorized, value-added reseller of DB/TextWorks and other Inmagic software.
We sell, support and develop solutions for managing information with DB/TextWorks, for searching it through WebPublisher PRO, and for managing a library with Genie.
Our Starter Kits for DB/TextWorks help you get started right away with this software with ready-to-use databases for managing library, archival and museum resources and operations.
We offer managed hosting of many Inmagic products, including web-based access to DB/TextWorks.
Learn more about:
![]()
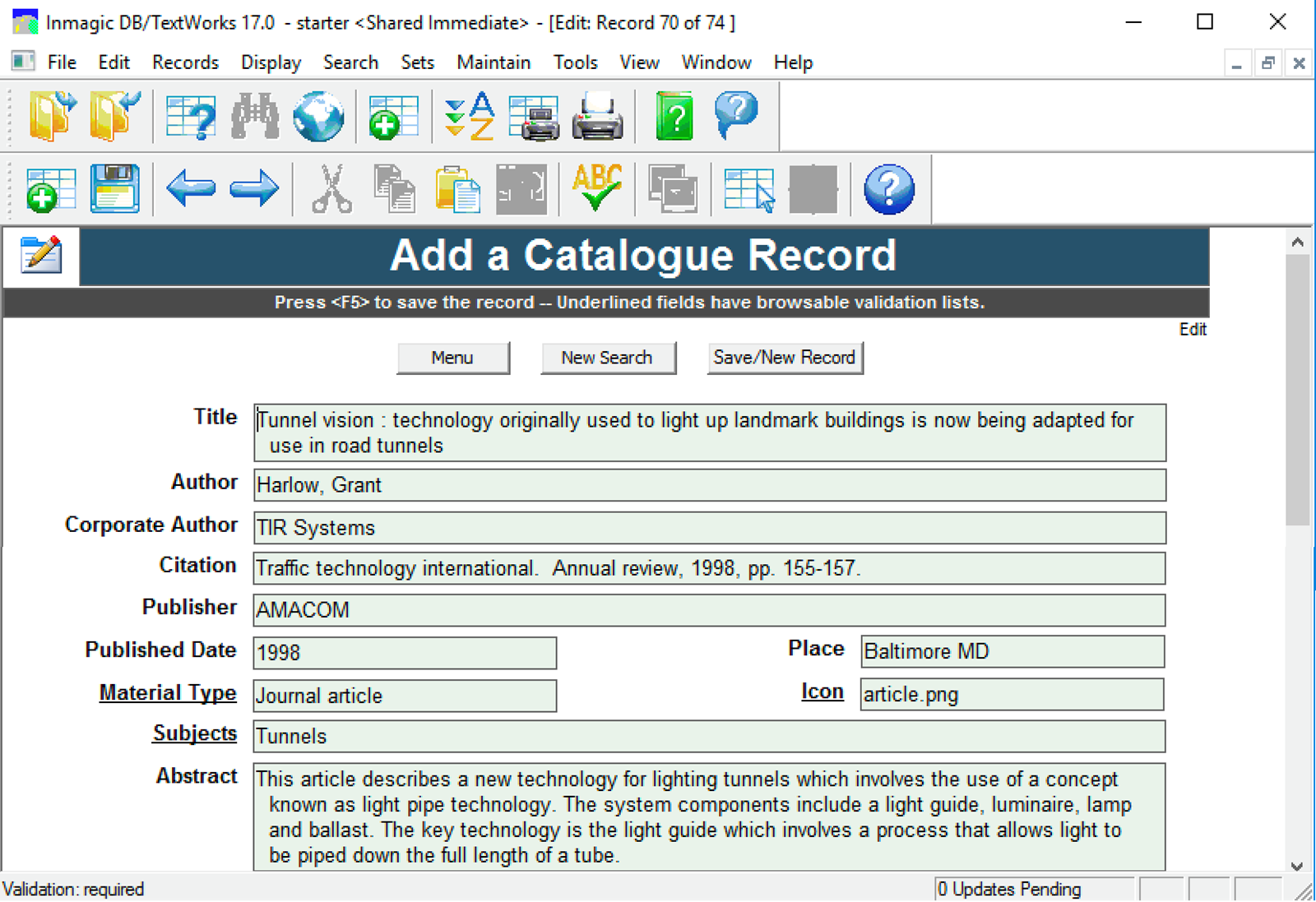
The Andornot Discovery Interface (AnDI) is a modern web-based search engine and discovery interface, ideal for indexing and searching diverse collections of information.
AnDI is used by libraries, archives, museums, law firms and other knowledge management organizations to index and search resources. It's a powerful search engine for cultural collections, able to index a wide variety of information and present it in a simple, easy to use format.
AnDI is available through Andornot's managed hosting services, or on-premises.
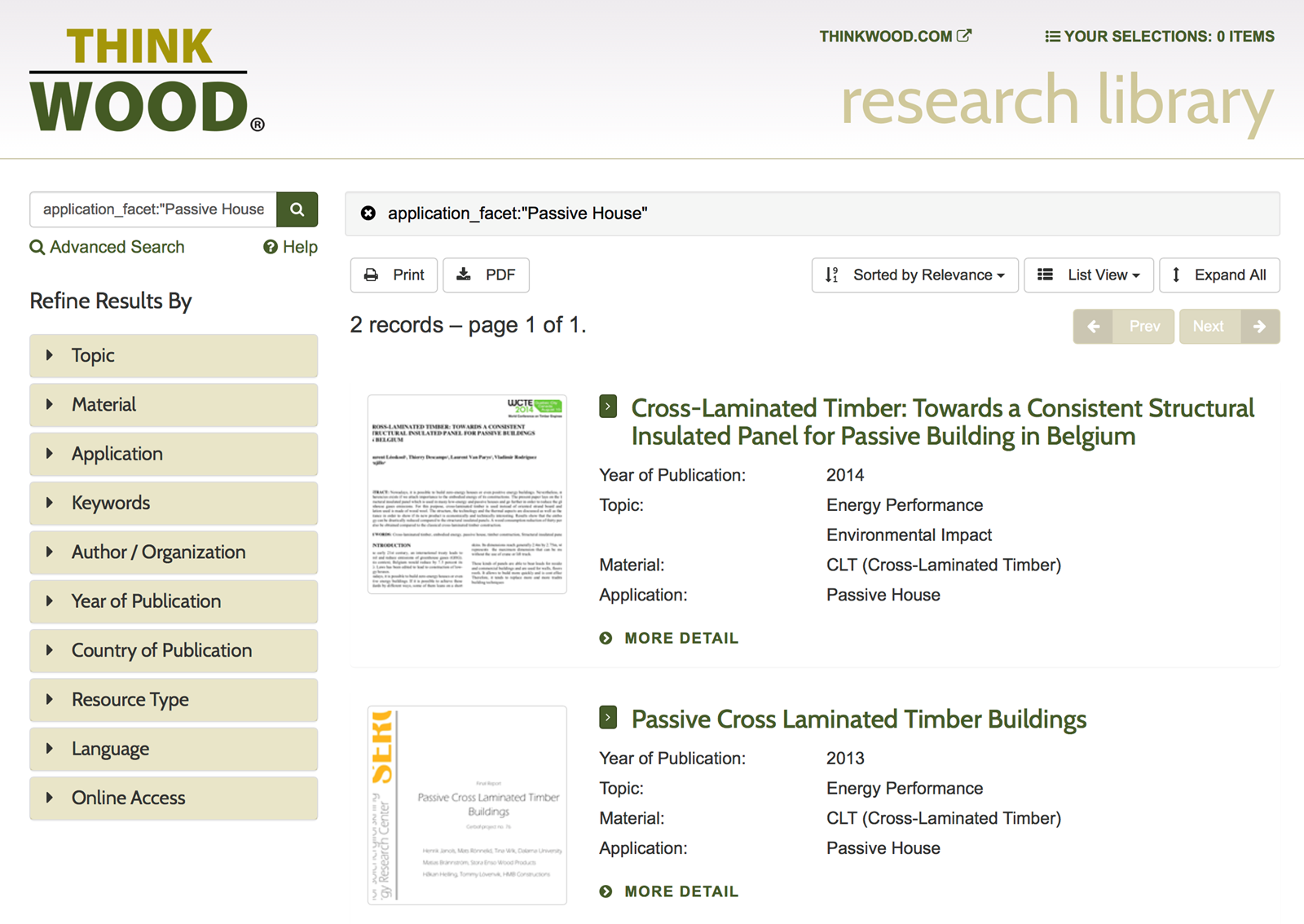
We regularly use open-source applications in our projects.
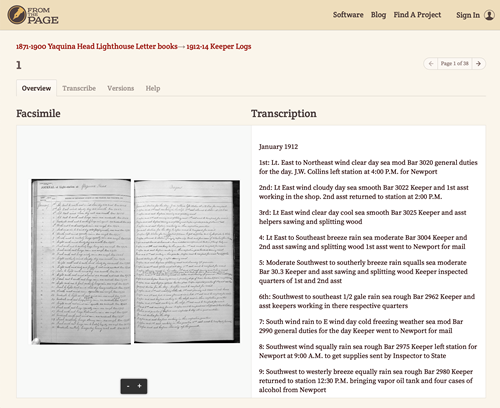
Every project we work on is unique: the client, their users, the budget, the required and desired features. We take all of these into consideration in designing systems and procuring software to fit her precise needs of each situation.
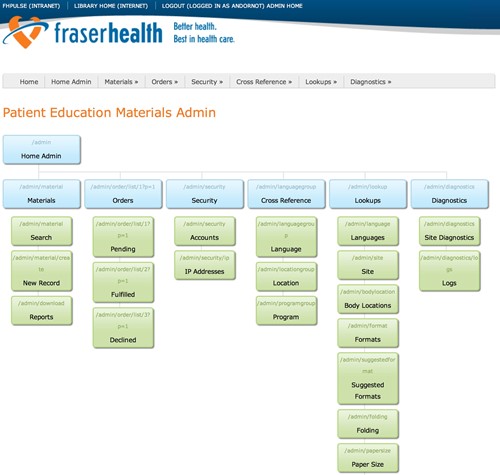 We love a challenge, and none more so than a problem in need of a software and information management solution. From patient education systems to accessible resources for the visually challenged, we’re experienced in assessing the needs of a project, designing a system and developing, testing and delivering it.
We love a challenge, and none more so than a problem in need of a software and information management solution. From patient education systems to accessible resources for the visually challenged, we’re experienced in assessing the needs of a project, designing a system and developing, testing and delivering it.
Learn more about these custom projects:
Andornot has offered professionally managed hosting services from our Canadian data centre for over 25 years.

In a cloud, in an unknown location? Is it difficult to obtain support for your application from your own IT group? Are your servers slow or due for replacement? Why not let Andornot help by having us host your data and applications?
Let Us Help You!
We're Librarians - We Love to Help People